-
[자료구조] 해시(hash), 해시 함수, 해시 테이블Algorithm | Data structure/Theory 2023. 1. 17. 16:53
1. 개요
- 해시 : Key:Value의 구조를 갖는 자료구조를 의미한다. ex) 전화번호부 / 이름=key, 전화번호=value
- Key : 매핑 전 원래 데이터의 값
- Hash value : 매핑 후 데이터의 값(해쉬 테이블의 index)
- Hash table : (Index, value)의 집합
- Hashing : 매핑하는 과정

2. 해시함수
- 해시함수는 임의의 길이를 갖는 임의의 데이터에 대해 고정된 길이의 데이터로 매핑하는 함수를 말한다.
- 같은 입력 값(key)에 대해서는 같은 출력 값(index)가 출력 된다.
- 해시함수는 입력 값의 범위보다 출력 값의 범위가 좁은 경우가 많기 때문에 입력 값이 다르더라도 동일한 값이 출력될 수도 있다. 이러한 경우를 ‘충돌(collision)’이라고 하는데, 위 사진 예시의 hash function은 문자열 key의 length를 반환하는 해쉬함수의 경우 cake와 taco는 동일한 출력값 4로 충돌이 발생한다.
위 사진처럼 해쉬충돌이 발생하는 경우, 동일한 인덱스에 value가 담긴 배열이 생성되며 이 때는 동일한 index의 배열 안에서 선형검색이 이루어진다.(분리연결법) 때문에 해쉬구조의 시간 복잡도를 보통 O(1)이라고 말하지만, 엄밀히 말하면 시간복잡도가 상수는 아니다. 그러나, 전반적인 평균 시나리오 중심으로 판단했을 때 hash table의 시간 복잡도는 O(1)이라고 보아도 무방하기 때문에 보통 시간 복잡도를 O(1)라고 말한다.
3. 해시 자료구조를 사용하는 이유
3.1 효율적인 데이터 관리
- 해시 충돌이 발생할 가능성이 있더라도 해시 테이블을 사용하는 이유는 적은 리소스로 많은 데이터를 효율적으로 관리할 수 있기 때문이다.
- 예를 들어, 해시 함수로 하드 디스크나 클라우드에 존재하는 무한에 가까운 데이터(키)들을 유한한 해시값으로 매핑함으로써 작은 크기의 캐쉬 메모리로도 프로세스를 관리할 수 있게 된다.
3.2 빠른 데이터 처리
- 색인(index)에 해시값을 사용함으로써 모든 데이터를 살피지 않아도(선형탐색) 검색과 삽입/삭제를 빠르게 수행할 수 있다. 위 그림 예시의 해시함수에 ‘pizza’를 입력하면 5라는 인덱스가 생성된다.
- 해시 함수는 언제나 동일한 해시값을 리턴한다. 따라서 해당 인덱스만 알면 해시 테이블의 크기와 무관히 데이터에 빠르게 접근할 수 있으며 색인은 계산이 간단한 해시함수로 작동하기 때문에 매우 효율적이다.
- 다르게 표현하면 배열은 시간 복잡도가 linear 하지만, 해쉬 구조는 시간 복잡도가 상수, O(1)이다.
- 📌 시간복잡도란?
알고리즘의 로직을 코드로 구현할 때, 시간 복잡도를 고려한다는 것은‘입력값의 변화에 따라 연산을 실행할 때, 연산 횟수에 비해 시간이 얼마만큼 걸리는가?’라는 말
효율적인 알고리즘을 구현한다는 것은 바꾸어 말해 입력값이 커짐에 따라 증가하는 시간의 비율을 최소화한 알고리즘을 구성했다는 이야기이다. 그리고 이 시간 복잡도는 주로 빅-오 표기법을 사용해 나타낸다.
출처 : https://hanamon.kr/알고리즘-time-complexity-시간-복잡도/
4. 해시테이블
- 해쉬함수를 사용하여 키를 해시값으로 매핑하고 이 해시 값의 인덱스 주소 값과 키를 함께 저장하는 자료구조를 해시 테이블이라고 한다.
- 충분히 큰 공간을 할당 받은 다음 해시함수를 이용하여 고유 색인(index)을 생성한다.
- 그리고 이 고유 인덱스와 맞는 위치에 데이터를 저장(매핑)한다.
- 인덱스 주소와 값이 저장되는 곳을 버킷(bucket) 또는 슬롯(slot)이라고 한다.
위 그림의 각 버킷에는 아래와 같은 데이터가 저장된다.
index
(hash value)data 00 01 (Lisa Smith, 521-8976) 02 (John Smith, 521-1234) 03 … … 13 14 (Sandra Dee, 521-9655) 15 - 위 테이블과 같이 해시 테이블은 Data 값이 비어있는 index 값이 존재한다.
- 키의 전체 개수와 동일한 크기의 버킷을 가진 해시 테이블을 Direct-address table이라고 한다.
4.1 Direct-Address Table
4.1.1. 장점
- 키 개수와 해시테이블의 크기가 동일하기 때문에 해시 충돌문제가 발생하지 않는다.
4.1.2 단점
- 예시 그림을 보면, 전체 키의 개수는 10개(K+U)이다. 때문에 해시 테이블(direct address table)도 동일한 크기의 버킷을 갖기 때문에 10개(T)이다. 하지만 실제 사용하는 키(actual keys)가 전체 키(universe of keys)보다 적을 경우에는 사용하지 않는 키(U-K)들을 위한 메모리도 할당되어야 해서 메모리 효율성이 떨어진다.
따라서, Direct-address table의 메모리 효율성 문제로, 보통 Direct-address table보다는 “해시 테이블 크기(m)가 실제 사용하는 키 개수(n)보다 적은 해시테이블”을 운용한다.
5. 해시 충돌
- 하나의 원 데이터는 하나의 해시값(index)만 가지지만, 하나의 해시값을 만들어낼 수 있는 원본 데이터는 매우 많다. 따라서 해시값만 가지고는 원본을 복원해내는 것은 불가능하다. 따라서 비밀번호, 전자서명, 전자투표, 전자상거래와 같은 민감한 정보의 무결성을 검증할 때 사용한다.
5.1 해시 충돌의 예시
- 해시 테이블을 활용한 해싱은 0 ~ 10까지 데이터를 담을 수 있는 리스트(해시테이블)을 생성하고 ‘cake’이라는 단어에 해시함수를 적용하여 ‘4’라는 인덱스가 생성되면 리스트 4번 인덱스에 ‘cake’를 저장하는 방식이다.
- 해시 함수는 언제나 동일한 입력에 대해 동일한 값을 반환하므로 ‘cake’를 입력하면 항상 ‘4’라는 인덱스가 나오므로 해당 인덱스를 통해 바로 원 데이터에 접근할 수 있다.
- 이때, ‘taco’ 라는 단어의 해시 값이 ‘4’로 나온다면 cake와 동일한 인덱스를 갖는 해시 충돌이 발생한다.
5.2 해시 충돌 해결 방법
- 해시 테이블의 크기를 유연하게 만들어 해결하는 분리 연결법(Separate Chaning)과 해시 테이블 크기는 고정시키되 저장해 둘 위치를 잘 찾는데 관점을 둔 개발 주소법(Open Addressing)이 있다.
5.2.1 분리 연결법
- 한 버킷 당 들어갈 수 있는 엔트리 수에 제한을 두지 않는 방법으로 모든 자료를 해시테이블에 담는다.
- 해당 버킷에 이미 데이터가 있다면 체인처럼 노드를 추가하여 다음 노드를 가리키는 방식(linked list)으로 구현한다.
- 만약 동일 index로 인해 해쉬 충돌이 발생하면 그 index가 가리키고 있는 linked list를 선형 검색하여 해당 key에 대한 데이터가 있는지를 검색하여 리턴한다.
- key를 삭제하는 것 역시, key에 대한 index가 가리키고 있는 linked list에서 그 노드를 삭제하면 된다.
5.2.2 개방 주소법
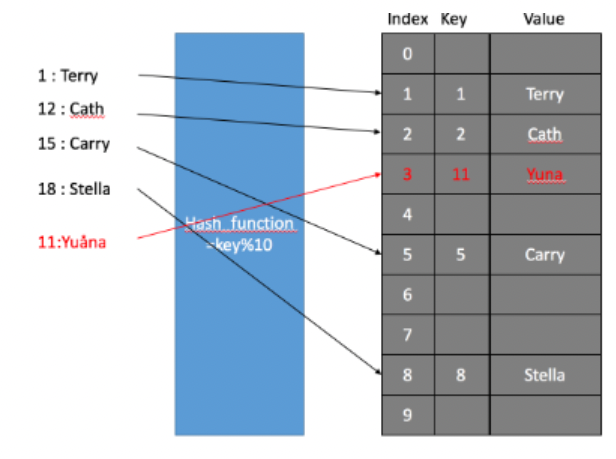
- chaining과 달리 한 버킷 당 들어갈 수 있는 엔트리가 하나 뿐인 해시 테이블을 사용한다.
- 해쉬 테이블 배열의 빈 공간을 사용하는 방법이다.
- 개방 주소법의 단점은 삭제가 어렵다는 것이다. 삭제를 한 경우 충돌에 의해 뒤로 저장된 데이터는 검색이 안될 수 있다.
- 개방 주소법에는 가장 간단한 Linear Probing(선형조사) 방식이 있다.
- Linear Probing 방식은 index에 충돌이 발생했을 때, index 뒤에 있는 버킷 중 빈 버킷을 찾아서 데이터를 매핑하는 방식이다.
- 11을 키로 하는 데이터가 해시 함수를 거쳐 1이 키인 데이터와 충돌이 발행했을 경우(아래그림) Linear Probing에서는 아래 그림과 같이 충돌이 발생한 index(1)뒤의 버킷에 빈 버킷이 있는지를 검색한다. 2번 버킷은 이미 index(2) 값이 매핑되어 있고 3번 버킷이 비어있기 때문에 3번과 매핑한다.
- 검색할 때는 array[1]인 배열을 검색하는데 1번 리스트의 키가 1이므로 다음으로 선형 조사를 하여 키가 11인 값을 찾아 접근할 수 있게 된다.
참고
- 개발자라면 꼭 알아야할 Hash Table 의 모든 것! : https://youtu.be/HraOg7W3VAM
- 해싱, 해시함수, 해시테이블 : https://ratsgo.github.io/data%20structure&algorithm/2017/10/25/hash/
- [암호학] 해시함수, 해시 알고리즘, 해시 충돌, 해시 자료구조 : https://yjshin.tistory.com/entry/%EC%95%94%ED%98%B8%ED%95%99-%ED%95%B4%EC%8B%9C-%ED%95%A8%EC%88%98-%EC%9E%91%EC%84%B1-%EC%A4%91'Algorithm | Data structure > Theory' 카테고리의 다른 글
DFS(Depth-First Search) (0) 2023.04.11 Stack / Queue / Recursive function (0) 2023.04.11 구현 : 시뮬레이션과 완전 탐색 (0) 2023.04.07 Greedy (0) 2023.04.05 [자료구조] 자료구조를 배우는 이유 (0) 2023.01.19
